The reality is load balancing can be confusing. Some applications require sticky load balancing (like the portal), some require shared file system access (like the document repository), some require an external load balancer (like the image server), and some are load balanced internally by the portal (like most custom portlets). So not surprisingly, some customers approach load balancing with trepidation, or perhaps they just expect implementing it will require mad voodoo engineering skills.
Enter Grid Search. The 6.1 version of the search server was rewritten with a raft of design changes including improved scalability. Previously it didn't fully scale. Now it has a tool called the Search Cluster Manager, which tells the story, right?
Actually, though the Search Cluster Manager's name correctly says "we can cluster," it gives many people a false idea about how clustering works. Administrators use the Search Cluster Manager to add a new search node to the cluster, but that's it. The Search Cluster Manager isn't required at runtime for end users who need their queries managed across the multiple nodes in the cluster. This component would be better named something like "Search Cluster Administration." Those who are used to configuring components to sit behind load balancers frequently expect the portal needs to connect to the cluster manager to serve content from the nodes.
In fact, when an administrator installs a new search node and adds it to the cluster through the Search Cluster Manager, the product goes on auto-pilot, and the load balancing is done. When the portal had only one search node, it was configured in the Search Server Manager to use that single node as the search cluster contact node. The magic is that after adding a second node, the contact node doesn't need to change. The search server is smart enough to notify the portal of any other node participating in the cluster. So the portal knows all the servers toward which it can distribute search traffic.
When you click the Search Service Manager's "Show Status" button, you can verify that it knows of all your nodes even though it's configured to use just one of them as the Cluster Contact Node. Note that at the bottom of the page, each node is listed:
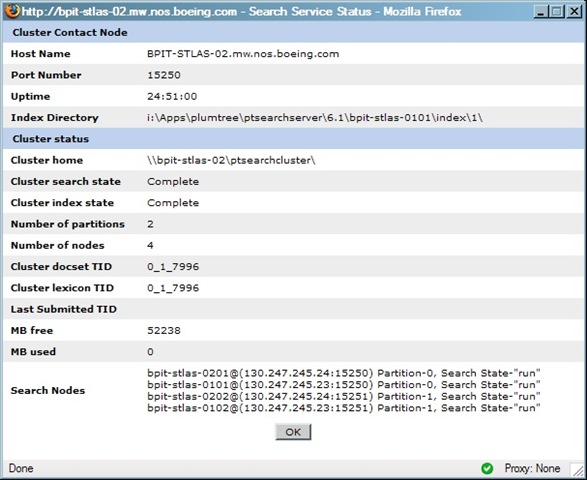
You can read a full document I put together that several people have told me provides useful enhancement to the standard documentation. It discusses installation, creation of nodes, the rationale behind your choices as you do this, and a little bit on load balancing. Feel free to download the file.